Python爬虫基础之广西人才网的信息爬取(1) - 简单爬虫
最近刚学习了Python的语法,迫不及待想做自己的第一个爬虫了,这里记录自己编写一个简单的爬虫程序爬取广西人才网的过程
前期准备
1.拟定好要爬取的数据,因为这是第一次做爬虫,简单爬取一下广西人才网上各大编程语言的招聘信息,以每个岗位的标题为准,之后再做扩展
2.分析网页结构,来到广西人才网首页,如图所示,在分类中找到本次要爬取的岗位分类,都是开发类:
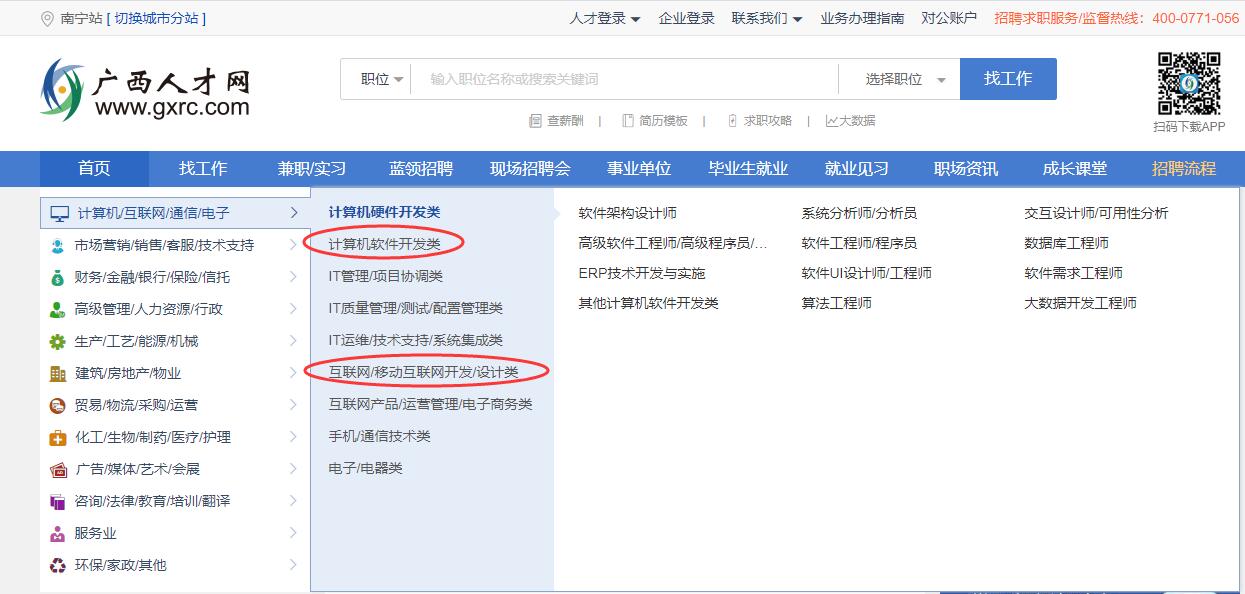
点进这两个分类的,可以看到浏览器URL栏中他们的URL分别为:
https://s.gxrc.com/sJob?schType=1&expend=1&PosType=5480
https://s.gxrc.com/sJob?schType=1&expend=1&PosType=5484
点击进去,可以看到如图的页面:
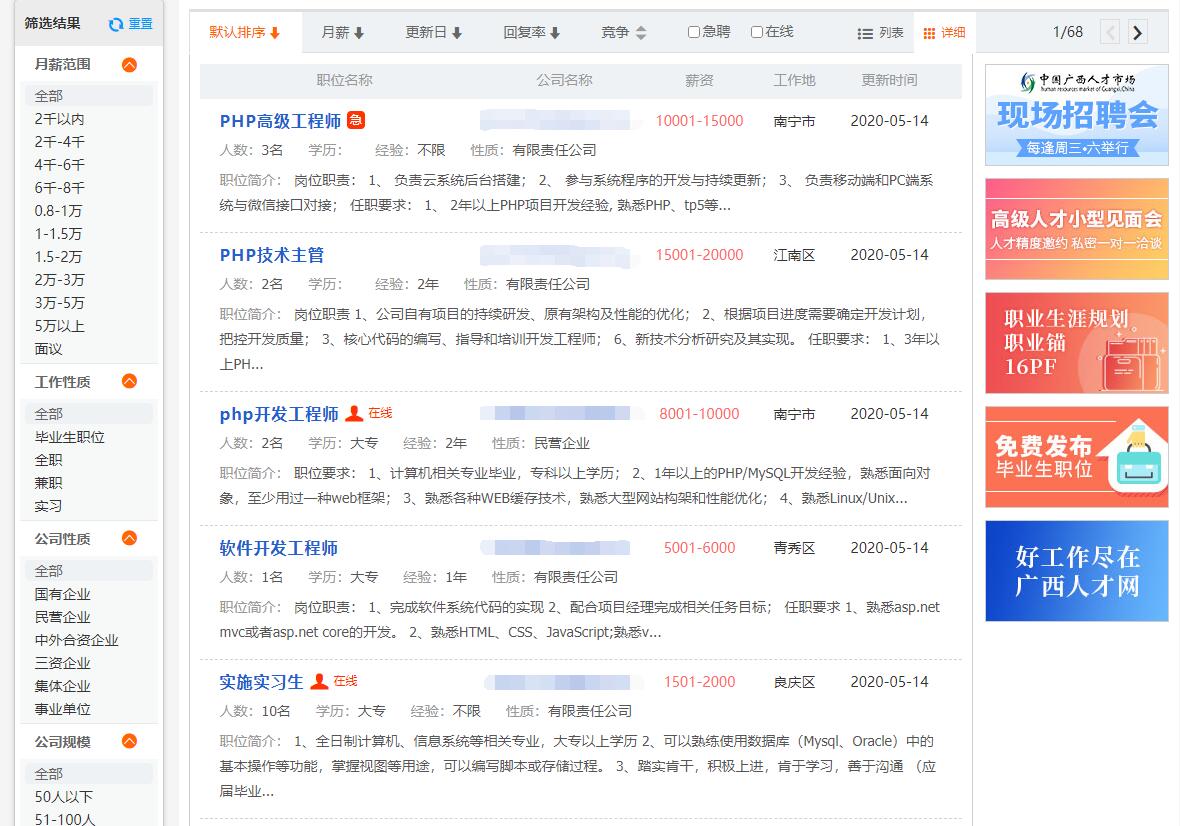
可以看出,本次,我们主要需要爬取分析的就是这些岗位的标题部分,以及薪资部分,这两个分类,每个分类都有几十页,这里如何获取到每一页的URL呢,我们试着跳转到本分类的下一页,可以看到,URL变成了https://s.gxrc.com/sJob?schType=1&expend=1&PosType=5480&page=2
再多往后面后面翻几页,可以印证我们的猜想,这个网站各分类中每一页的岗位信息分别为: https://s.gxrc.com/sJob?schType=1&expend=1&PosType=岗位类型&page=页码
开始编写代码
1.这里直接上代码,关于Beautiful Soup具体用法和如何查看页面中元素的标签这里不再赘述,网上有详细教程,不在此篇讨论范围之内
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
from bs4 import BeautifulSoup
import urllib.request
from collections import OrderedDict
# IT类工作地址
listTypes = ['5480', '5484']
jobsNum = []
jobList = ["c#/.net", "java", "php"]
dicResult = OrderedDict()
# 伪装浏览器头部
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/81.0.4044.138 Safari/537.36'
}
for type_number in listTypes:
url_prefix = 'https://s.gxrc.com/sJob?schType=1&expend=1&PosType=' + type_number + '&page='
# Request类的实例,构造时需要传入Url,Data,headers等等的内容
request = urllib.request.Request(url=url_prefix + '1', headers=headers)
first_page = urllib.request.urlopen(request)
soup = BeautifulSoup(first_page, 'lxml')
intLastPageNumber = int(soup.find('i', {"id": "pgInfo_last"}).text)
urls = [url_prefix + str(i) for i in range(1, intLastPageNumber + 1)]
for url in urls:
request = urllib.request.Request(url=url, headers=headers)
page = urllib.request.urlopen(request)
search_result = BeautifulSoup(page, 'lxml').find_all(name='div', attrs='rlOne')
bolTypeRight = False
for job in search_result:
tag_a = job.find('a')
href = tag_a.get('href')
company = job.find('li', 'w2').text
salary = job.find('li', 'w3').text
jobName = tag_a.text.lower()
if href not in jobsNum:
jobsNum.append(href)
for jobType in jobList:
if '-' in salary:
if '/' in jobType:
bolTypeRight = jobType.split('/')[0] in jobName or jobType.split('/')[1] in jobName
else:
bolTypeRight = jobType in jobName
if bolTypeRight:
if jobType not in dicResult.keys():
dicResult[jobType] = [int(salary.split('-')[0])]
else:
dicResult[jobType].append(int(salary.split('-')[0]))
print(company + " " + jobName + ":" + salary + " " + href)
print('广西人才网IT岗统计结果(按岗位标题)')
print('总岗位数量:' + str(len(jobsNum)))
for resultKey, value in dicResult.items():
print(resultKey + '岗位总数量:' + str(len(value)) + ',平均工资(按岗位最低工资为准):' + str(sum(value) / len(value)))
本文由作者按照 CC BY 4.0 进行授权