Java异步编程漫游
原本计划分享ZooKeeper,但作为许多基础组件的组件,它离运维越来越近,离业务开发越来越远,以至于不容易找到或者举出什么真实的业务例子来介绍Zookeeper在实际工作中应该如何使用(比如虽然它可以拿来做分布式锁,却不是首选)。加上我并不认为短短的一个小时能介绍完ZooKeeper的重要内容,经过一番抉择之后,最终决定分享Java异步编程的相关内容,也是一个科普 + 知识漫游。
一、前言
在程序中发起请求是一个很常见的操作,访问数据库,发送邮件,使用搜索引擎时,我们都在发起请求。网络的使用极大扩展了我们的程序能力,但与此同时也需要付出代价,在使用网络进行通信的分布式架构下,我们需要承担网络故障和延迟可能对我们造成的影响,并且每个服务经常需要维护多个传入和传出的网络连接。 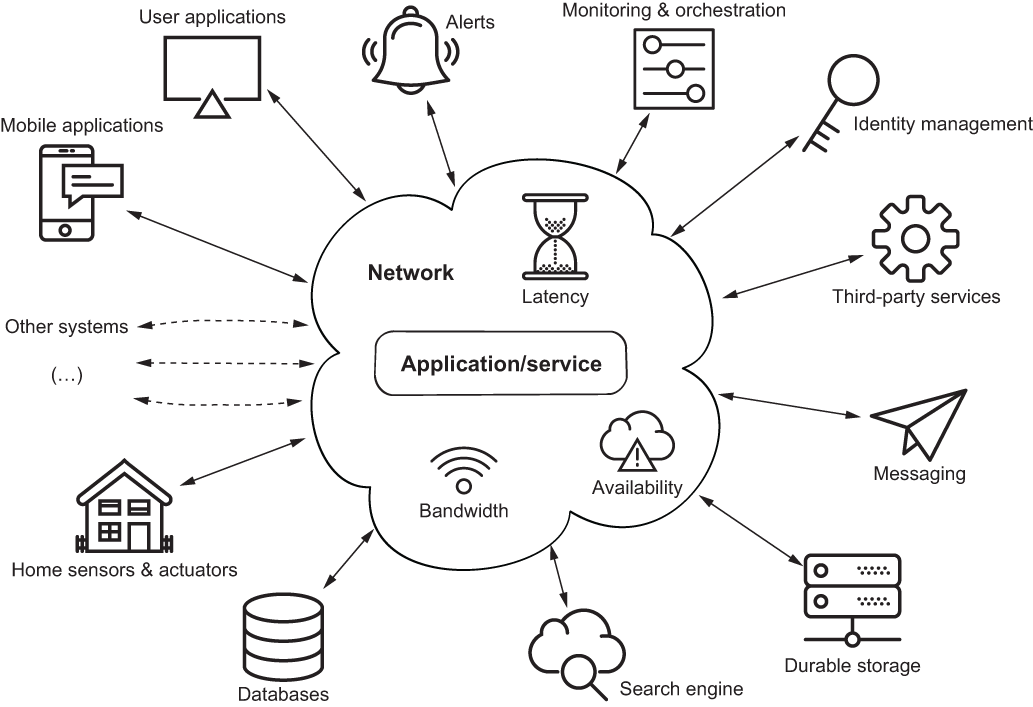
在编程时遇到需要同时处理多个网络请求时,应该采用什么策略呢,我们从简单的阻塞API讲起。
一、简单的阻塞API
服务需要管理多个请求时,传统且普遍的形式就是为每个连接都分配一个线程,很多框架或者组件也是用的这样的模型,比如:Python的Flask,Spring(在3.0之前),ASP.NET(现在也叫ASP.NET Core,在4.5版本之前)。
这种模式的优点是简单,因为它是同步的,但是弊端也很明显。我们来看这张图:
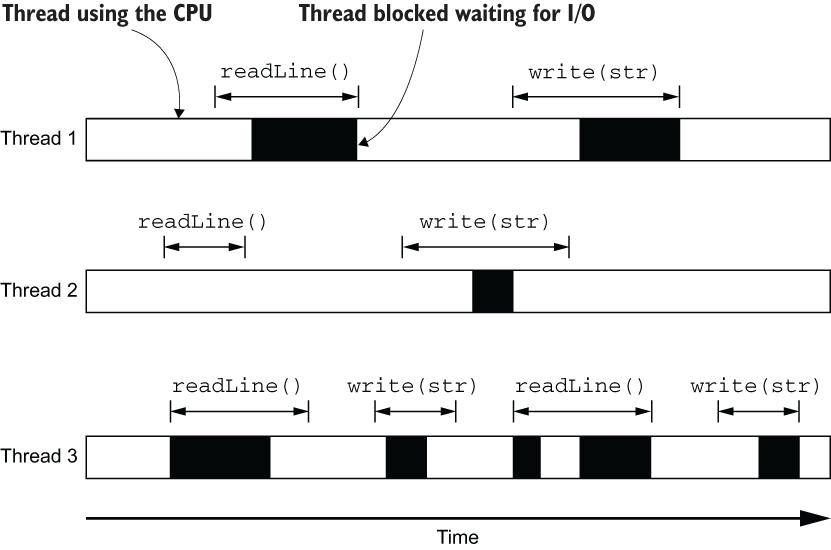
使用阻塞模型时,线程干等着网络IO,什么也干不了,虽然这些等待中的线程不处于运行状态,也不占用任何CPU资源,但线程在操作系统中绝对不是廉价的资源。线程需要消耗内存(比如JVM的 -Xss参数就是用来设置为每个Java线程分配的栈内存大小,在64位操作系统下,一个Java线程通常会被分配1MB大小的线程栈),并且操作系统为了调度线程,频繁进行线程切换也需要消耗CPU资源。
虽然可以引入线程池来减轻开启新线程的代价,但无论如何,还是很容易出现需要的线程数比线程池的可用线程数要高的情况,当成千上万的请求一下子到来的时候,这种方案的局限性是显而易见的。
二、基于非阻塞IO的异步编程
为了解决同步阻塞IO带来的种种问题,Java标准库引入了NIO相关包。
Java标准库的NIO提供了Channel,Selector等抽象,其工作模式像这样(这里写while(true)只是想说明当前只用了一个线程在循环处理):

上图中的Selector会调用内核的I/O多路复用器(select(),poll(),或Linux特有的epoll(),这部分具体的工作原理相对比较深,本次「漫游」就不涉及到这些内容了,想深入了解的建议读一下《Linux/UNIX系统编程手册》这本书中的相关内容)。
NIO的思路是先请求一个操作(阻塞的IO操作),然后继续执行其他任务,直到操作结果已经准备好了,再继续回过来继续进行后续操作。在这个模型中,可以有许多并发连接在单个线程上多路复用,我们可以看一段使用NIO的Java代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
public static void main(String[] args) throws IOException {
Selector selector = Selector.open();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open
serverSocketChannel.bind(new InetSocketAddress(3000));
// 将Channel设置为非阻塞模式
serverSocketChannel.configureBlocking(false);
// 将Channel注册到Selector上,监听连接事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select();
// 获取所有已经就绪的SelectionKey(所有提醒事件)
Iterator<SelectionKey> it = selector.selectedKeys().iterator();
while (it.hasNext()) {
SelectionKey key = it.next();
if (key.isAcceptable()) {
// 有新的连接
newConnection(selector, key);
} else if (key.isReadable()) {
// Socket有数据可读
echo(key);
} else if (key.isWritable()) {
// Socket再次可写
continueEcho(selector, key);
}
// 处理完毕后,需要从就绪集合中移除当前key,否则下次循环还会进来
it.remove();
}
}
}
Java从很早之前(在Java1.4中引入)就有了NIO(non-blocking IO)的包,但我们极少直接与其打交道。从上面代码我们可以看出来,和阻塞IO相比,直接使用NIO进行编程复杂程度会大大增加,并且最主要的是,和Java的很多标准库一样,java.nio只关注它的作用,不提供更高级别的特定于协议(比如HTTP)的帮助类,也没有规定线程模型(对于非阻塞IO编程来说,一个合适的线程模型更能充分发挥它的优势),直接基于java.nio编程无异于刀耕火种,并且维护成本高。
因此,像Netty,Apache MINA这样的网络编程库的出现,就是为了解决Java标准NIO库的这些短板(它们都是基于Java NIO的,并且进行了进一步的封装(例如为多种协议提供了专门的编解码器,简化了协议处理的复杂性)和优化(例如通过池化,零拷贝等技术进一步进行资源和性能优化),简化了网络编程的复杂性)。
三、Event Loop
我们本次主要讨论Java异步编程的发展,所以不对详细的库(如Netty,Vert.x等)做过多介绍,Event Loop作为各种Java异步编程库中最流行的一种机制,我们有必要了解一下它是如何提高资源利用率,而在Event Loop中我们又是怎样进行编程的。
关于Event Loop我们可以看这张图,Event Loop其实很简单,一个单独的Event-Loop线程一直循环,各种不应该阻塞线程的事件被触发时(例如数据准备就绪的I/O事件,计时器被触发的事件等)再进行处理(处理这个事件的线程可以是当前的Event Loop的线程,也可以是另外的线程,不同的框架有不同的选择,例如Netty就提供了多种线程模型供选择,而Vert.x则选择直接使用Event Loop线程作为处理线程)。
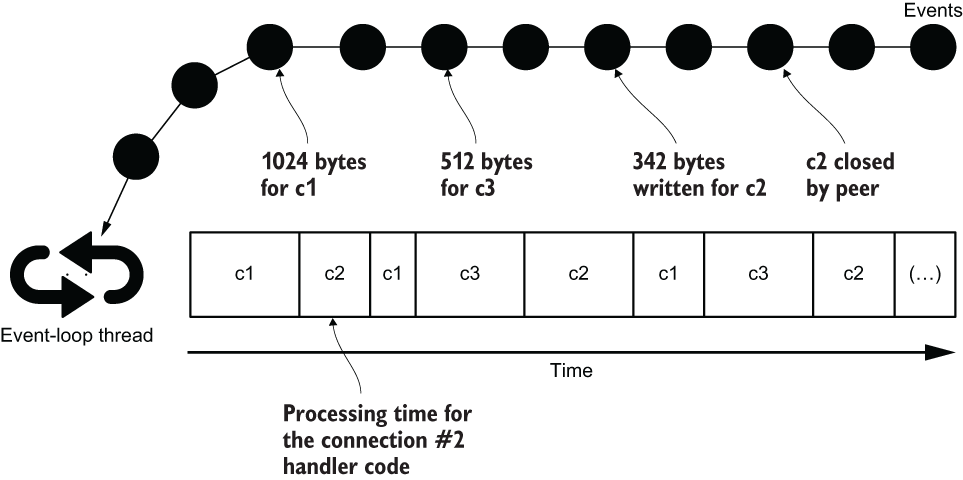
了解前端编程的朋友应该知道,Event Loop是JavaScript中的一个重要概念,这与两方面原因有关(当然这两方面原因可能也有因果关系)。首先,因为JavaScript是单线程的(这里要注意,浏览器本身的运行是多线程的,不要将两者混淆),同一时刻只会有一段JS代码在运行;其次,在GUI编程中,单线程事件驱动的机制几乎是一个通用法则,因为如果想用多线程进行更新,用锁等机制保证线程安全的话,最终总是特别容易陷入死锁(总是会有多个调用试图访问一些绘图相关的共享数据),因此使用Event Dispatch线程,或者被叫做UI线程来进行界面相关操作。
得益于巧妙的线程机制,服务端领域的Node.js也总是可以用少量资源应付大流量访问。
「当事件被触发时,再进行处理」,意味着在异步编程中代码不总是从上到下依次执行的,而是「穿插」执行的,使用Event Loop时,通常有两种编程风格:
3.1 回调
当提到回调时,很多人会马上想到「回调地狱」,(甚至于有一个网站就叫做Callback Hell),它也是很多JavaScript程序员痛苦的原因,举个简单的例子,这是基于Vert.x框架编写的一段代码,用于从三个部署在localhost的传感器(Sensor)服务中获取数据,汇总数据后请求一个快照(snapshot)服务将这些数据保存下来,保存完成后对客户端请求进行响应:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
List<JsonObject> responses = new ArrayList<>();
AtomicInteger counter = new AtomicInteger(0);
for (int i = 0; i < 3; i++) {
webClient
.get(3000 + i, "localhost", "/")
.expect(ResponsePredicate.SC_SUCCESS)
.as(BodyCodec.jsonObject())
.send(ar -> { // 并行对传感器服务发起请求
if (ar.succeeded()) {
responses.add(ar.result().body());
} else {
logger.error("Sensor down?", ar.cause());
}
// 三个请求都已完成(注意,这段代码位于上面send函数的回调中)
if (counter.incrementAndGet() == 3) {
JsonObject data = new JsonObject()
.put("data", new JsonArray(responses));
webClient
.post(4000, "localhost", "/")
.expect(ResponsePredicate.SC_SUCCESS)
.sendJsonObject(data, ar1 -> { // 发送数据给快照服务
if (ar1.succeeded()) {
// 响应当前请求
request.response()
.putHeader("Content-Type", "application/json")
.end(data.encode());
} else {
logger.error("Snapshot down?", ar1.cause());
request.response().setStatusCode(500).end();
}
});
}
});
}
虽然嵌套层级并不是很深,但是不是感受到「地狱」的味道了?事实上,借助一些编程时的技巧,很容易让嵌套看起来没那么可怕,比如上面的那段代码中,我们可以将三个请求都已经完成后进行操作的后续代码提取出来作为一个单独的函数,按照这种思路,往往可以有效避免看到一个被嵌套成「金字塔」的函数,即:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
List<JsonObject> responses = new ArrayList<>();
AtomicInteger counter = new AtomicInteger(0);
for (int i = 0; i < 3; i++) {
webClient
.get(3000 + i, "localhost", "/")
.expect(ResponsePredicate.SC_SUCCESS)
.as(BodyCodec.jsonObject())
.send(ar -> { // 并行发送给传感器服务的请求
if (ar.succeeded()) {
responses.add(ar.result().body());
} else {
logger.error("Sensor down?", ar.cause());
}
// 三个请求都已完成
if (counter.incrementAndGet() == 3) {
JsonObject data = new JsonObject()
.put("data", new JsonArray(responses));
// 发送数据给快照服务
sendToSnapshot(request, data);
}
});
}
过多使用回调确实让代码更不易读了,但是最大的问题还不在这里,最大的问题在于原本的功能实现代码和异步协调代码结合得太深了,很难一眼从代码中看出来这三个请求是并行发出的,并且所有请求的结果将会被组装然后返回。
3.2 Future
在介绍Event Loop时提到的Future与后文会提到的Java标准库中的Future有区别,注意不要混淆。
看过回调的代码后,我们再来看同样是Vert.x中一种叫做Future的抽象,和其名称一样,「未来」,用于保存一个操作的结果,而这个结果在当下没有意义,当执行完成后,会通过其定义的handler进行通知,借助这种抽象,我们就可以很容易将异步操作包装成看得见摸得着的对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
private void handleRequest(HttpServerRequest request) {
// 并行发起并等待三个对传感器服务的请求
CompositeFuture.all(
fetchTemperature(3000),
fetchTemperature(3001),
fetchTemperature(3002))
.flatMap(this::sendToSnapshot)
.onSuccess(data -> request.response()
.putHeader("Content-Type", "application/json")
.end(data.encode()))
.onFailure(err -> {
logger.error("Something went wrong", err);
request.response().setStatusCode(500).end();
});
}
private Future<JsonObject> fetchTemperature(int port) {
// 请求传感器服务,并将结果作为一个Future返回
return webClient
.get(port, "localhost", "/")
.expect(ResponsePredicate.SC_SUCCESS)
.as(BodyCodec.jsonObject())
.send().map(HttpResponse::body);
}
private Future<JsonObject> sendToSnapshot(CompositeFuture temp
List<JsonObject> tempData = temps.list();
JsonObject data = new JsonObject()
.put("data", new JsonArray()
.add(tempData.get(0))
.add(tempData.get(1))
.add(tempData.get(2)));
return webClient
.post(4000, "localhost", "/")
.expect(ResponsePredicate.SC_SUCCESS)
.sendJson(data)
.map(response -> data);
}
四、其他异步编程内容
4.1 CompletableFuture与ForkJoinPool
日常使用多线程编程时,我们可以注意到当进行ExecutorService.submit()后我们会得到一个Future对象,其允许我们获取异步计算的结果,Future是在Java 5引入的(包含在java.util.concurrent内,java.util.concurrent也是这个版本引入的)。
有趣的是,上文中提到了Java1.4引入了NIO,Java从1.5版本开始对外推广的版本号中就直接去掉了主版本号前面的部分,直接称为Java 5,Java 6等,而在对外推广的版本中也从来没出现过Java 3,Java 4这两个版本。
| Java内部发行版本 | 发布时间 | Java对外推广版本号 |
|---|---|---|
| JDK 1.0 | 1996年1月 | Java 1.0 |
| JDK 1.1 | 1997年2月 | Java 1.1 |
| JDK 1.2 | 1998年12月 | Java 2 |
| JDK 1.3 | 2000年5月 | Java 2 |
| JDK 1.4 | 2002年2月 | Java 2 |
| JDK 1.5 | 2004年9月 | J2SE 5.0 |
| JDK 1.6 | 2006年12月 | Java SE 6 |
| JDK 1.7 | 2011年7月 | Java SE 7 |
| JDK 1.8 | 2014年3月 | Java SE 8 |
这是一段Future的使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService executorService = Executors.newFixedThreadPool(1);
// 使用 Future 进行异步相加操作
Future<Integer> futureResult = executorService.submit(() -> {
// 模拟耗时操作
Thread.sleep(1000);
return 1 + 2;
});
System.out.println("Doing other work...");
// 阻塞等待任务完成
Integer result = futureResult.get();
System.out.println("Result: " + result);
executorService.shutdown();
}
而Java 8中引入了CompletableFuture,除了原有的Future接口外,其还实现了CompletionStage接口,使得其API更加丰富和灵活,支持链式调用,组合操作,并且有回调机制,异常处理机制等,以下是一个CompletableFuture的使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
public static void main(String[] args) {
// 使用 CompletableFuture 进行异步相加操作
CompletableFuture<Integer> completableFuture = CompletableFuture.supplyAsync(() -> {
// 模拟耗时操作
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return 1 + 2;
});
System.out.println("Doing other work...");
// 链式调用,通过 thenApply 处理异步操作的结果
CompletableFuture<String> resultFuture = completableFuture.thenApply(result -> {
System.out.println("Result received: " + result);
return "Processed Result: " + result;
});
// 异步操作完成后的回调
resultFuture.thenAccept(processedResult -> {
System.out.println("Final Result: " + processedResult);
});
// 防止主线程提前退出
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
上面的代码肯定会让你感到奇怪,CompletableFuture的创建并没有指定线程池,它是如何实现异步的呢,首先要说明的是,CompletableFuture是可以自定义线程池的:
1
2
3
4
ExecutorService customExecutor = Executors.newFixedThreadPool(10);
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
// 执行任务的代码
}, customExecutor);
但是这不是重点,重点是若没有指定的线程池,其会默认使用ForkJoinPool线程池来执行异步任务。
ForkJoinPool ForkJoinPool是一种基于工作窃取(work-stealing)算法的线程池实现,在Java 7中被引入,通常用于处理可以分解为较小任务的问题,这张图可以简单说明工作窃取算法的工作原理:

每个工作线程都有自己的双端队列用于存储任务。当一个线程完成自己队列中的任务后,它可以从其他线程的队列末尾“窃取”任务执行,从而保持线程的工作状态。这样的设计有助于充分利用 CPU 资源,提高并行计算效率。
CompletableFuture默认使用ForkJoinPool.commonPool(),它是一个共享的全局线程池,如果被其他任务占用,可能会影响性能,因此如果有必要,需要创建自己的ForkJoinPool实例。
4.2 Reactive Extensions
Reactive extensions(这里讨论的是Java实现,后面直接表述为RxJava)是一套基于观察者模式的扩展库,最开始在.NET平台上流行起来,后面越来越多的语言和技术栈都开始使用(不仅在服务端,并且还有各种客户端界面库也使用它,比如WPF,Android等),具体可以参考ReactiveX。
在这里不对其做深入介绍,但举个简单的例子你就能体会到其强大之处,假如现在你从数据库中获取一些用户信息,然后将这些信息按照一定规则进行处理:
传统同步代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import java.util.List;
public class UserService {
public List<User> getUsers() {
// 同步获取用户列表的数据库操作
List<User> users = DatabaseService.getUsersFromDatabase();
// 处理用户数据
List<UserInfo> userInfos = processUserList(users);
// 返回处理后的结果
return userInfos;
}
private List<UserInfo> processUserList(List<User> users) {
// 处理用户信息的业务逻辑
// ...
return processedUserInfos;
}
}
使用RxJava的异步代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import io.reactivex.Observable;
import io.reactivex.schedulers.Schedulers;
public class UserService {
public Observable<UserInfo> getUsersAsync() {
// 异步获取用户列表的数据库操作
return Observable.fromCallable(() -> DatabaseService.getUsersFromDatabase())
.flatMapIterable(users -> users)
.subscribeOn(Schedulers.io())
.observeOn(Schedulers.computation())
.map(this::processUser);
}
private UserInfo processUser(User user) {
// 处理用户信息的业务逻辑
// ...
return processedUserInfo;
}
}
在这段代码中,除了创建Observable(可观察对象),还有后续的链式处理函数外,最亮眼的莫过于subscribeOn(Schedulers.io())以及observeOn(Schedulers.computation()):
subscribeOn(Schedulers.io())将数据获取的流程切换到I/O线程上进行。observeOn(Schedulers.computation())将后续的处理过程又放到计算线程上执行。
使用RxJava时,并不直接操作Thread或者ExecutorService,而是操作像上面一样名为调度器(Schedulers)的抽象API,使用调度器,可以非常流畅迅速地在不同类型的线程上进行切换,大大提高了异步编程的效率和容错率。并且其不局限于特定的线程模型,在上文中提到的Vert.x框架中也有对应的RxJava库。
Reactive除了是一种异步方案之外,还是一种编程思想,在不需要进行异步编程的时候也可以使用,有兴趣的可以通过上面的链接进一步了解。
4.3 背压(Back-pressure)
背压是一种消费者向生产者发出信号的机制,用于提醒生产者正在用比自己处理速度更快的速度发送数据(也有相当多的文章说背压应该是一种问题而不是机制,个人比较赞同的说法是「在编程世界中,背压是一种Web应用中的常见问题,而久而久之,人们也用这个术语来表达处理这类问题的机制」),有几张图片可以很形象地描述背压: 


从第二个图片中可以看出,当没有正确处理好背压的时候,慢消费者就会被生产者压垮。
那为什么要在异步编程中单独提起背压呢,因为在使用阻塞模型时,生产者天然被阻塞(设想Spring Boot线程池中的所有线程都处于正在处理请求的状态),只能等待消费者完成处理(即使有更多请求,当超过一定数量时,也会被Spring Boot所拒绝,例如在使用Tomcat时,对应配置项为server.tomcat.accept-count,代表启用的线程数达到最大时,接收排队的请求个数)。因此在使用阻塞模型时,背压并不是什么显著的问题。
而根据前文的描述,使用非阻塞IO时,为了提高吞吐量,必然会一股脑接收大量生产者的所有消息,等到有空的时候再进行处理,这种操作非常容易引发背压,而缓存起来的消息最终会造成消费者自身的OOM。
为了应对这种情况,各种异步框架都有自己的背压机制,大体上分为三类:
- 控制(Control),以各种方式协调生产者,从源头减少流量(类似TCP协议中使用滑动窗口进行流量控制;
- 缓冲(Buffer),将多余的消息暂时存储起来,之后再处理,但是当生产者速率持续高于消费者时,缓冲始终不是长久之计,例如会像上面说的一样造成OOM,当然,利用Kafka等外部消息队列,能创建出更大的进程之外的缓冲区
- 丢弃(Drop),在权衡利弊,允许丢弃部分消息的情况下,这往往是最快速有效的办法
最近我在实际工作中也遇到了背压问题:在持续压测设备消息上报时,我的服务需要请求设备服务获取设备详情,而此时设备服务也处于被压测的情况下,偶尔会处于短暂不可用状态,由于
Vert.x官方的WebClient暂时没有直接帮忙做处理,因此发向设备服务的请求会在一瞬间大量积压,很快就造成OOM,服务重启。因此在很多情况下,由于异步框架的默认实现不能覆盖所有情况等原因,背压依然是需要结合实际情况去手动处理的。
五、Java虚拟线程
Java 21已经于2023 年9月19日正式发布,作为目前最新的LTS版本,其可能也会是近些年来最重要,影响最大的Java版本,因为其带来的虚拟线程这一特性,为Java程序员打开了新世界的大门。
作为一个使用过其他带有语言级别异步编程模型的程序员,最开始接触Java时,对Java的各种库为了实现异步编程从过去到现在所做的那么多努力,发明的那么多花式编程方式感到诧异,「这在C#里面,就是个
aysnc加await就能解决的,这都是些啥啊,搞那么麻烦」。不过好在终于,属于Java自己的JVM级别的异步编程支持来了。
5.1 什么是Java虚拟线程
要想知道什么是Java虚拟线程(在很多其他语言中也被称为协程,用户态线程等),我们首先需要分清平台线程和虚拟线程之间的区别:
平台线程 平台线程可以看作是JVM对操作系统线程的一层薄的封装,可以直接理解为系统线程,被操作系统内核管理。一个系统能同时调度的线程是有限的,并且线程切换也会消耗CPU资源,所以通常被认为是一种重量级资源。
虚拟线程 而虚拟线程则不同,虽然其仍在操作系统线程上运行,但其不由操作系统管理,而是由JVM管理和调度,是一种用户态线程,不需要在内核态和用户态之间来回切换,非常轻量级。
当代码在虚拟线程中执行阻塞I/O的操作时,JVM其将其挂起,直到可以继续执行为止。简单来说就是在一个虚拟线程阻塞时自动切到另一个虚拟线程。虚拟线程的实现方式与虚拟内存类似,JVM将大量虚拟线程映射到少量系统线程,并且由JVM自行调度进行切换。
而Java虚拟线程的核心就在于这个调度的过程,这个过程主要由Continuation实现,这个词经常在协程理论中出现,它就是协程的本质,为程序提供了暂停/继续 (yield/resume)的能力。
5.2 如何使用虚拟线程
关于这部分的代码,官网和网上已经有不少示例,这里直接把官网的示例贴上来,这里最想表达的是,Java作为一个生态强大的语言,它的虚拟线程考虑到了对很多现有代码的兼容性和改造成本,因此尽可能和以前的线程创建方式接近,我想这也是为什么Java使用了现在的实现而不是其他语言中的协程实现:
使用Thread.ofVirtual()创建一个虚拟线程并等待:
1
2
Thread thread = Thread.ofVirtual().start(() -> System.out.println("Hello"));
thread.join();
指定ExecutorService类型(不难想象很多代码使用这种方式就能很快改造完成):
1
2
3
4
5
try (ExecutorService myExecutor = Executors.newVirtualThreadPerTaskExecutor()) {
Future<?> future = myExecutor.submit(() -> System.out.println("Running thread"));
future.get();
System.out.println("Task completed");
// ...
5.3 注意事项
不要池化虚拟线程 上面也提到,虚拟线程是很轻量的用户态线程,创建和切换过程中并不会产生那么大的开销,池化反而会导致性能受限。虽然官方文档也这么建议,但情况不能一概而论。比如上面提到过的背压问题,这个问题在虚拟线程中也是容易出现的,这时候池化反而是一个可选的方案。
避免长期且频繁的synchronized块 当前虚拟线程的实现决定了其在遇到synchronized块时无法进行调度,会阻塞宝贵的系统线程。因此应该在使用协程时应避免出现时间较长并且比较频繁的synchronized块,若是改造原有代码,也需要留意以前的代码实现是否存在这种情况,而官方也提供了一些方法用于探测是否存在这样的代码。
虚拟线程性能就一定更好吗 事实上,作为一种「用户态线程」,我们可以说虚拟线程的实现比之前的提到的EventLoop更官方,相对来说更底层(JVM自动调度),但是不能一定就认为使用虚拟线程就一定更好或者更快。
相反的,在以往其他语言的开发经验中,因为创建协程的代价过于低廉,很多程序员实际上不清楚什么时候该使用它,或者使用它会产生什么后果(甚至于混淆协程与线程的概念,使用协程进行CPU密集形的任务),随意滥用虚拟线程或者协程导致的是调试难度增加以及诡异的问题增多。
这不是说虚拟线程就不强大,使用方便本身就是它的一大优势,不然的话也不会有很多人认为这是对以前那些异步编程库的一次大冲击了(我也这么认为,当虚拟线程出现后,之前围绕着异步I/O开发的各种库和编程方式都显得没那么有必要)。
5.4 展望
目前来看,对于原本就使用了过去的那些异步编程框架的程序来说,改造成虚拟线程的提升不会那么大,并且由于编程风格的变化,改造难度也会更大。相反以前使用同步模型的服务改造阻力反而会更小。
当然,仍然有不少框架需要重写或者适配,才能发挥出虚拟线程的作用,这里可能有疑惑,明明JDK已经尽量避免和原来使用线程的模式产生差异了,原来我开一个普通线程去调他们的库,现在开一个虚拟线程去调他们的库就好了,使用方改不就好了,为什么还需要重写?因为过去很多库为了提高吞吐,都会采用Event Loop结合限量线程池的方式自己做一些处理。而现在要调整和优化的代码,也正好是这些代码。因此才说原本就采用同步模型的库反而改动更小。
关于这方面的展望在知乎上的问题「如果java虚拟线程稳定了,是不是有一大批框架和工具要重写?」当中,也有不少讨论和见解: ![[java-async-11.png]]
Project Loom 是 OpenJDK 的一个子项目,致力于为 Java 引入轻量级线程(称为 Virtual Threads 或者 Loom Threads)。Loom 的目标是在不改变现有 Java 程序的前提下,为 Java 增加纤程的能力。Loom 的设计目标是实现一个高效且易用的协程和轻量级线程模型,以解决 Java 并发编程的挑战。 Java的虚拟线程就是Loom项目孵化的。
![[java-async-12.png]]
![[java-async-13.png]]
六、实战
一次实践,原有的项目侧设备数据流转使用单消费者 + 单生产者进行数据转发,导致吞吐量始终达不到接近IoT侧的地步(但是由于已满足性能指标,就没有继续优化)。
在这里基于原有项目建立两个demo分支,直接使用JDK 21,并使用上面提到的多线程与虚拟线程技术,对比资源消耗及性能提升情况。
尚未完成
参考
[异步编程 - ASP.NET 上的 Async/Await 简介 Microsoft Learn](https://learn.microsoft.com/zh-cn/archive/msdn-magazine/2014/october/async-programming-introduction-to-async-await-on-asp-net) [并发模型与事件循环 - JavaScript MDN (mozilla.org)](https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Event_loop) - 什么是 Event Loop? - 阮一峰的网络日志 (ruanyifeng.com)
- Virtual Threads (oracle.com)
[异步编程场景 - C# Microsoft Learn](https://learn.microsoft.com/zh-cn/dotnet/csharp/asynchronous-programming/async-scenarios) - Java虚拟线程的核心: Continuation - 知乎 (zhihu.com)
- 虚拟线程调度执行流程及原理 - 掘金 (juejin.cn)